«На разработку уже потратили миллионы тенге». Интервью с одним из создателей казахской языковой ИИ-модели


Армен Атаян родом из Армении. Долгое время он был бизнес-ангелом и инвестировал в различные стартапы. С появлением GPT-3 стал увлекаться искусственным интеллектом, а после создал компанию Gen2B.ai, которая помогает внедрять ИИ в бизнес-процессы. Полгода назад по приглашению Бахта Ниязова Армен переехал в Казахстан, чтобы разработать национальную языковую модель с открытым исходным кодом – Irbis GPT. В июне состоялся официальный релиз продукта. На данный момент Irbis GPT скачали более 35 тысяч раз.
Digital Business пообщался с Арменом и узнал, на каких данных обучалась казахская языковая модель и сколько средств потребовалось для ее создания. Также мы одни из первых протестировали IrbisGPT.
«Казахстан, на мой взгляд, – самое перспективное государство в СНГ в сфере цифровых инноваций»
– Как давно вы работаете в сфере искусственного интеллекта?
– В 2022 году, когда появилась модель GPT-3 (davinci-002), решил отправить запрос на получение доступа. Тогда она была закрыта для общего пользования, и, казалось, что мою заявку отклонят. Однако получил апрув и принялся за изучение. Кстати, нашему Head of AI доступ в GPT-3 дали еще в июле 2020 года. И сделал это лично президент OpenAI Грег Брокман.
Вообще, тема с ИИ меня очень вдохновила. Я понимал, какие изменения нас ждут в будущем. Соединил LLM с чат-ботом в Telegram и показывал друзьям, что он может грамотно отвечать на вопросы. Тогда мало кто разделял мой восторг.

После появилась отдельная ИИ-модель для генерации кода, получил доступ и к ней. Тогда понял, что хочу профессионально развиваться в этой сфере. Перестал инвестировать в чужие стартапы и запустил свой – Gen2B.ai. Сейчас занимаемся созданием платформы, которая совмещает в себе различные ИИ-продукты собственной разработки. Например, один из наших продуктов Gen2Call обрабатывает звонки в колл-центр, а также автоматически выявляет пользователя, который оставил продукты в корзине на сайте и не совершил покупку.
– Что мотивировало вас переехать в нашу страну?
– Около трех лет жил на Бали, там познакомился с Бахтом Ниязовым. Однажды он пригласил меня в Казахстан в MOST Hub. Проникся атмосферой этого места, увидел, как работают Astana Hub, МФЦА. Также посетил Digital Bridge 2023, где мы с командой могли свободно общаться с министрами. В частности, мне удалось презентовать свои решения Канышу Тулеушину (первый вице-министр МЦРИАП – прим. Digital Business), Саясату Нурбеку (министр науки и высшего образования – прим. Digital Business) и Багдату Мусину (экс-глава Минцифры – прим. Digital Business).

Понял, что Казахстан – именно та страна, в которой я запущу проект своей жизни. Тем более, на мой взгляд, Казахстан – самое перспективное государство в СНГ, и у него больше шансов занять лидирующие позиции в сфере цифровых инноваций и технологий.
«Провели много бессонных ночей и, несмотря на сжатые сроки и отсутствие качественных датасетов, прошли полный цикл обучения языковых моделей»
– С чего началась работа над IrbisGPT?
– С идеи. Однажды мы с Бахтом и Павлом Коктышевым обсуждали будущее развития языковых моделей и их безопасность. Я сказал, что использовать модели, которые находятся на серверах зарубежных организаций, небезопасно и нужно создавать собственные. Кто-то спросил, сможем ли мы сделать казахстанскую модель? У Gen2B имелся подобный опыт, методология и экспертиза: мы фокусировались на создании LLM для внутреннего использования различными предприятиями и правительствами в том числе. Ответил «да», но попросил немного времени, чтобы посовещаться с командой.

Однако буквально через несколько дней вышел анонс о скором появлении IrbisGPT. Наш Head of AI сначала даже запаниковал, т.к. понимал, насколько большой объем задач предстоит проделать за короткое время. Но мы поняли, что нужно просто взять и начать работать. Провели много бессонных ночей и, несмотря на сжатые сроки и отсутствие качественных датасетов, прошли полный цикл обучения языковых моделей. Результаты превзошли наши ожидания. Сегодня у IrbisGPT в совокупности 35 тысяч скачиваний.
– На что ушло больше всего времени?
– В основном на исследования. Изучали опыт других стран, в том числе нам помогали создатели Chinese-LLama (китайская языковая модель – прим. Digital Business). После тестовых обучений поняли, что опция взять готовую модель, загрузить туда набор данных и сделать fine-tuning (адаптация и дополнительное обучение общедоступной готовой модели для конкретных задач – прим. Digital Business) нам не подходит. Дело в том, что зарубежные нейросети разрабатывались под латинскую группу языков, и поэтому GPT-4 на казахском работал в 5 раз медленнее.
Первое, что мы сделали – обучили свой токенайзер для повышения эффективности модели. Далее загрузили большое количество текстов на казахском языке, чтобы нейросеть на их основе быстрее и качественнее находила закономерности. Так, в IrbisGPT одно казахское слово равняется одному токену. Сейчас такое же соотношение показывает GPT-4o на английском языке, но там, например, слово «рахмет» весит три токена. В более старых версиях один токен вообще обозначал только одну казахскую букву.
На переобучение ушло около трех недель, а наша гипотеза о том, что эффективность модели после этого повысится, подтвердилась.
– Откуда брали данные на казахском языке?
– Значительная часть датасета – информация с казахской Википедии, которая находится в общем доступе. Также мы брали данные из любых открытых ресурсов, которые находили. Часто приходилось пользоваться Google-переводчиком. Ужасный датасет, на самом деле, так как точность перевода оставляет желать лучшего. Но у нас была цель сделать базовую демонстрационную модель, которая разбирается в грамматике казахского языка и корректно составляет слова в предложения, сохраняя общий смысл. На большее не могли рассчитывать за три недели обучения.

При этом мы запрашивали датасет Национального корпуса казахского языка, чтобы наполнить IrbisGPT большим количеством качественной информации. Она находится в открытом доступе на сайте qazcorpus.kz. Мы обратились к Министерству науки и высшего образования РК с просьбой предоставить информацию в удобном формате. К сожалению, нам отказали. Причины до сих пор неизвестны.
– А где планируете хранить модель?
– Недавно Минцифры заявило о приобретении большого суперкомпьютера, нам также обещали предоставить доступ к нему. Надеемся, в будущем это решит вопросы с вычислительными мощностями.
«Если мы хотим создать LLM наподобие ChatGPT, это требует минимум $10 млн»
– Сколько человек работает над IrbisGPT?
– Команда децентрализована. Есть люди из Португалии, Сербии, Грузии, Таиланда России и, конечно, Казахстана – около 15 человек. Сотрудничаем с ребятами из Gen2B, MOST Hub и другими специалистами. После презентации проекта на CEVF 2024 получили много заявок от желающих присоединиться к разработке IrbisGPT. Сейчас активно рассматриваем обращения и будем рады новым членам команды.
– Какое количество средств требуется на создание национальной языковой модели?
– Если мы хотим создать LLM наподобие ChatGPT, это требует значительных финансовых вложений, примерно от $10 млн и больше. Однако, если сосредоточится на создании более логичных и прикладных моделей меньшего масштаба, затраты будут значительно ниже.
На разработку IrbisGPT уже потратили миллионы тенге. Это мои личные средства, Бахта Ниязова и MOST Holding.
– Для чего Казахстану нужна национальная языковая модель? Не проще ли дождаться, когда это реализует, например, OpenAI?
– Это особенно важно для национальной безопасности, чтобы данные граждан не покидали страну и обрабатывались внутри. Таким образом, языковые модели должны работать в закрытом контуре. IrbisGPT был создан именно для этого.

Также IrbisGPT нужен, чтобы у людей, говорящих на казахском, была возможность использовать родной язык для получения нужной информации. Обычно, если есть какой-то запрос, человек идет в Google и пишет его на русском или английском, потому что так быстрее можно получить ответ. С нашей моделью можно общаться на казахском языке.
Помимо этого нам было важно доказать, что мы можем эффективно и быстро создавать большие языковые модели. Это открывает пути на новые рынки. Мы готовы работать по всему миру, не ограничиваясь странами Центральной Азии.
– К слову о национальной безопасности. Стоит ли регулировать ИИ в Казахстане?
– Безусловно. На мой взгляд, после осознания возможных последствий от использования ИИ будет ужесточаться регулирование этой сферы по всему миру. Ведь уже есть успешные кейсы того, как с помощью нейросетей можно влиять на общественное сознание. Например, консалтинговая компания Cambridge Analytica с помощью нейросетей влияла на исход выборов в различных странах. В 2016 году во время Brexit компания создавала различные викторины и персонализированную рекламу, побуждающую голосовать за выход Великобритании из ЕС. Искусственный интеллект помогал таргетировать и распространять данный контент по определенным психографическим группам. Благодаря таким материалам люди голосовали за Brexit. Такого результата достигли с помощью обычных нейросетей, а сейчас появляются языковые модели, которые понимают человеческую логику. Это влияние определенно увеличится.

Представьте, крупная казахстанская компания внедрит ИИ в работу своих колл-центров. Клиенты будут звонить и в процессе разговора делать тот или иной выбор. В данных диалогах можно будет с высокой точностью отследить алгоритм принятия решения каждого человека, а после разработать инструменты по воздействию на целую нацию. Это, на наш взгляд, представляет довольно серьезную угрозу. Чтобы это предотвратить, необходимо фокусироваться на создании собственных, суверенных моделей, а также регулировать сбор, распространение и продажу датасетов. Важно понимать, какие данные можно продавать другим компаниям и странам, и для каких целей они будут их использовать.
«Только после четвертой или пятой итерации получили удовлетворяющий результат»
– Перейдем к тестированию системы. На какие запросы сейчас может отвечать IrbisGPT?
– Сейчас IrbisGPT отвечает на общие вопросы: например, расскажет, кто президент Казахстана или объяснит в чем смысл жизни. Взаимодействовать с системой на сайте (пока что доступна только десктоп-версия) можно как текстом, так и голосом. Также мы обучили голосовую модель для понимания казахского языка и добились точности 85%.
Однако модель также может работать с контекстом. Например, мы недавно загрузили текст Уголовного кодекса РК и задали несколько вопросов. Модель извлекла нужную информацию и ответила правильно.
Проверим, как это работает на конкретном примере.
1. В специальное поле загружаем текст, в котором рассказывается о биотехнологиях.
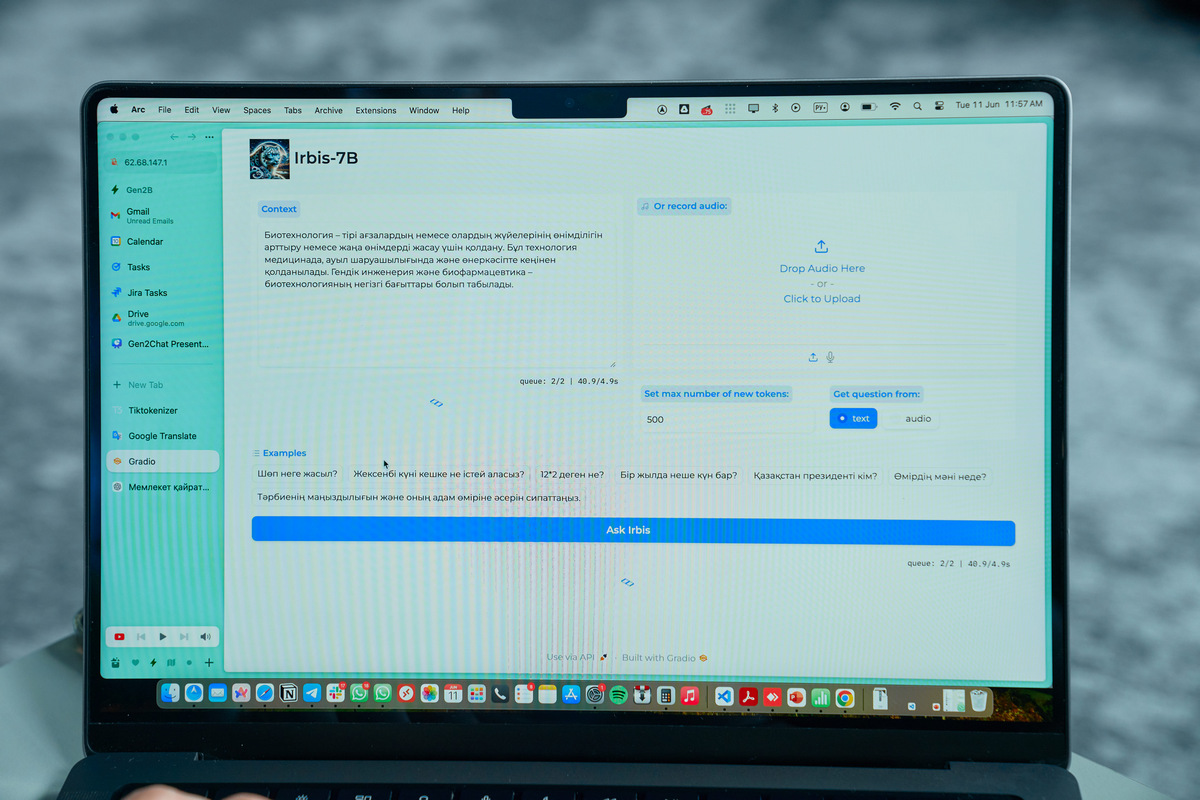
2. Задаем вопрос: «В каких областях используются биотехнологии?», и спрашиваем IrbisGPT.
3. Через несколько секунд получаем ответ: «в медицине, сельском хозяйстве и промышленности».
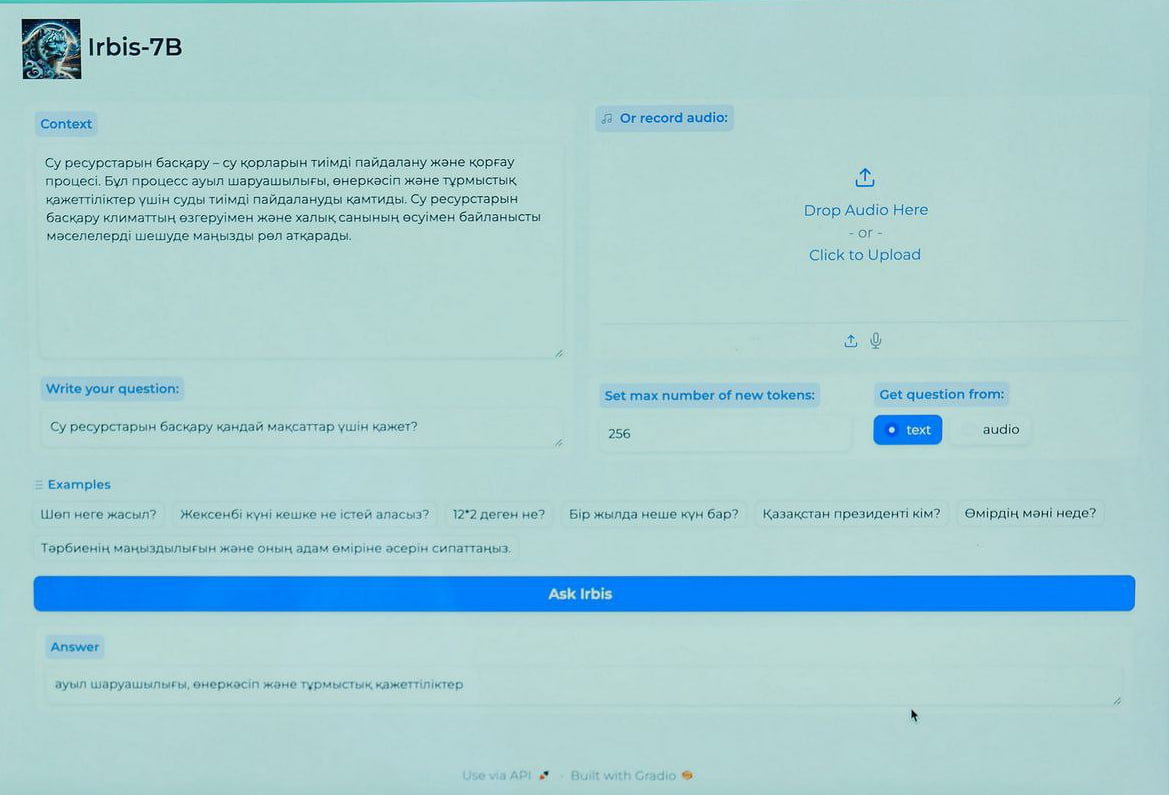
Сейчас мы вставили небольшой текст в поле контекста, но сюда можно загружать материалы объемом до 8 тысяч знаков.
– Какие дальнейшие планы по развитию IrbisGPT?
– Для релиза этой версии потребовалось создать несколько итераций. Лишь после четвертой или пятой попытки получили удовлетворяющий результат. Поэтому сейчас важно продолжать обучать модель, наполняя данными. Для этого, возможно, потребуются реальные переводчики на казахский язык, чтобы загружать качественные тексты, а не криво переведенные с помощью Google.
Сейчас у IrbisGPT 7 млрд параметров, а, например, у мультимодальной ИИ-модели Falcon 2, созданной в ОАЭ, – около 120 млрд. Поэтому, чтобы IrbisGPT мог решать большой спектр задач, необходимо загрузить примерно 30 млрд токенов качественный данных.
В планах создавать прикладные модели под разные цели. К примеру, для экстренных служб, образовательной сферы, госуслуг. В будущем хотели бы сделать мультимодальную модель, которая сразу будет обучена на всех типах данных: аудио, видео, текст и фото. Таким образом мы добьемся минимальной задержки.
– Развитие ИИ протекает очень стремительно. Смогут ли нейросети заменить человека?
– Рутинную работу ИИ точно автоматизирует. Возьмем, к примеру, пилотов. Раньше они полностью управляли самолетом от начала до конца, а сейчас больше напоминают операторов автопилота. Ни в коем случае не уменьшаю их вклад, но на данный момент они в большей степени контролируют процесс и вмешиваются, если что-то идет не так. Думаю, с программистами произойдет то же самое. Они станут операторами нейросетей, будут формировать архитектуру и задавать инструкции для создания кода, вместо того, чтобы писать его вручную.

В то же время профессии, в которых необходимо взаимодействие человека с человеком, а также где ценится творчество и процесс создания, станут более актуальными. Мы восхищаемся скульптурами Микеланджело, потому что не можем себе представить, как один человек мог из куска камня создать настолько детальные произведения искусства. Если мы воссоздадим подобные шедевры при помощи роботов и ИИ – это не вызовет такого же восторга.
Читайте также: Из Казахстана в Германию: начать с нуля и покорить Баден-Баден