AI-поиск: почему вашего сайта нет в ответах ChatGPT и Google Overviews


Раньше в SEO боролись за место в топе, но сегодня нейросети дают пользователям готовые ответы, не заставляя их скроллить выдачу. Что это меняет? Вместо «топовых» вариантов в ответах моделей могут всплывать разные площадки – порой менее раскрученные и даже стоящие в поиске ниже.
Тимлид группы SEO в инновационном digital-хабе Wunder Digital Елена Салтыкова рассказывает, как нейросети выбирают источники, почему AI игнорирует даже качественные сайты и что делать командам в Казахстане, чтобы их контент начал работать на новый тип поиска.
Откуда ChatGPT берет данные: три слоя информации
Нейросети оценивают сайты не так, как SEO-инструменты. Разные AI-системы используют разные источники. Но в целом языковые модели опираются на эти типы данных.
1. Обучающий массив – «базовое образование»
До запуска модель перерабатывает огромные объемы текстов из открытого интернета: сайты, книги, форумы, документацию. Она не хранит эти тексты дословно, а выучивает статистические закономерности: какие слова за какими обычно идут, какие факты сочетаются между собой. Это как фундамент, на котором строится все остальное.
2. Живой поиск в сети — «свежие новости»

Современные чат-модели (ChatGPT с поиском, Gemini, Claude) могут подтягивать актуальные данные через встроенные поисковые механизмы. Это нужно для быстро меняющейся информации: курсы валют, погода, цены, события. Ответ в таком случае – смесь из «старых знаний» модели и «новых находок» из поисковой выдачи.
3. Загруженные файлы и базы знаний – «временный черновик»
Когда пользователь прикрепляет к диалогу PDF, Excel или Word, модель получает дополнительный источник для ответа. А если компания подключает свою базу знаний (например, через RAG), нейросеть может работать как корпоративный ассистент. Но это локальная история: такие данные видны только в рамках конкретного диалога или для конкретного пользователя.
— ChatGPT не «серфит» по сайтам в момент каждого пользовательского запроса. Модель отвечает на основе двух вещей: либо того, что она усвоила во время обучения, либо результатов онлайн-поиска (если эта опция активирована). Поэтому шанс, что ваш материал повлияет на ответы AI, прямо связан с тем, насколько качественным и заслуживающим доверия источником его посчитают, — говорит Елена Салтыкова.

Тимлид группы SEO в инновационном digital-хабе Wunder Digital Елена Салтыкова
Чем лучше контент соответствует принципам E-E-A-T (об этом расскажем позже), чем больше на него ссылаются другие. А чем сильнее ссылочный профиль, тем выше вероятность, что похожие страницы окажутся в обучающей выборке модели или будут найдены через поиск в реальном времени.
У LLM-систем есть жесткие рамки, которые важно понимать:
- Корпоративные базы, платные архивы, личные кабинеты для них не существуют, если только пользователь сам не загрузил файл в диалог.
- Никаких данных о конкретном пользователе, его истории, местоположении (если он сам не сообщил об этом в чате).
- Модель не хранит в памяти URL или название источника. Она оперирует паттернами, а не закладками.
- Пока разработчики не переобучат модель или не подключат поиск в реальном времени, ее знания застывают на дате последнего обучения.
Итог: LLM выдает наиболее вероятный и логичный ответ, основываясь на тех связях, которые выучила в процессе обучения. Это не поисковая система в привычном смысле – это механизм правдоподобной генерации.
Как с той же задачей справляется Google
Он устроил работу иначе, чем обычные чат-модели. Google AI Overviews не генерирует ответ из «головы», система привязана к поисковому индексу. Языковая модель здесь играет вспомогательную роль – она только оформляет итоговый ответ и прикрепляет к нему ссылки.

Все источники, которые попадают в AI Overviews, – это обычные страницы из органического индекса Google. Те же самые, которые ранжируются в классической выдаче.
Процесс выглядит так:
1. Система получает сложный запрос от пользователя.
2. Она разбивает его на несколько подтем (это называется fan-out – «веерный выход»).
3. Для каждой подтемы из индекса извлекаются 1-3 релевантных документа (retrieval + semantic ranking).
Google официально заявляет (а исследования подтверждают): в AI Overviews работают те же принципы отбора, что и в обычном поиске. На попадание в генеративную выдачу влияют:
- Полнота раскрытия темы. Без воды и с четкими ответами на подвопросы.
- Авторитет. Сильный домен, полезный контент, экспертные авторы, узнаваемый бренд и качественные ссылки с других сайтов.
- Свежесть данных. Для цен, новостей, обзоров и всего, что быстро устаревает, Google отдает приоритет недавно обновленным материалам.
- Но к этому списку добавляется еще один критерий – удобство извлечения информации. Система оценивает, насколько легко «вытащить» конкретный факт со страницы.
В интерфейсе ссылки на источники видны прямо рядом с блоками текста (или под ними). Пользователь может кликнуть и перейти на сайт.
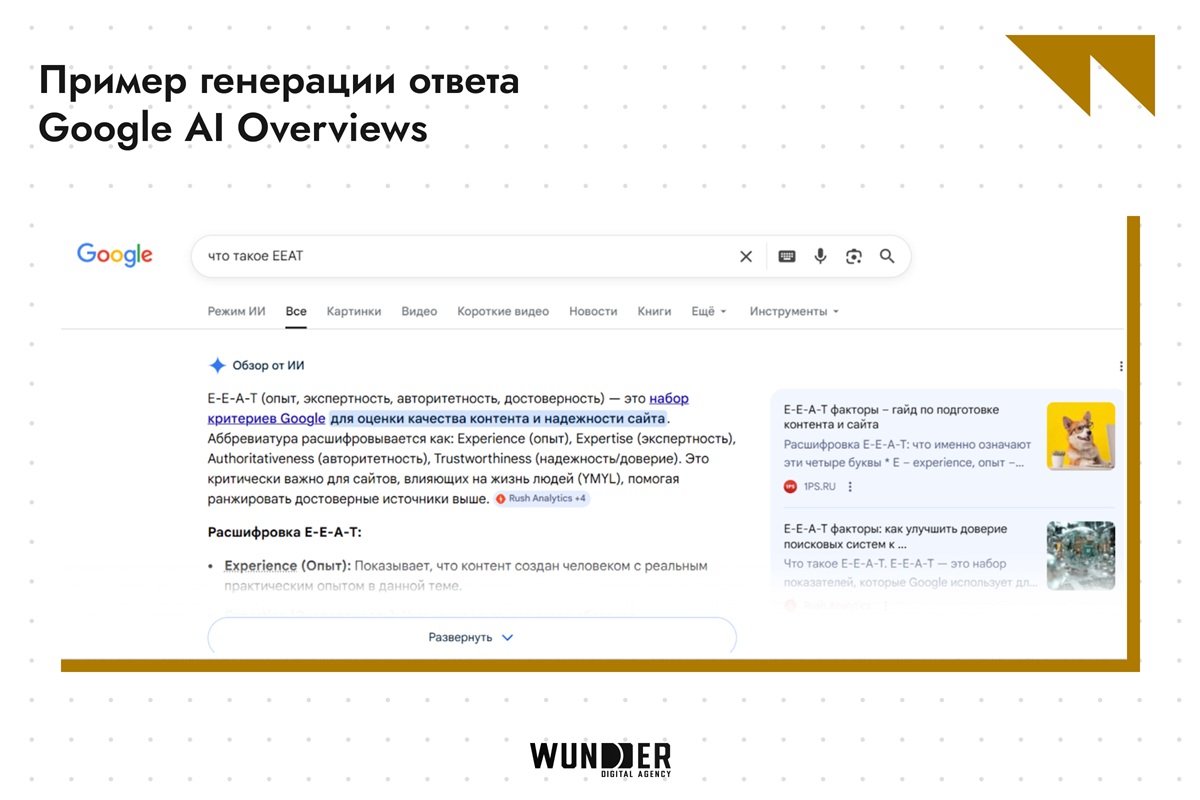
Что повышает шансы попасть в AI Overviews (по опыту специалистов и советам для вебмастеров):
- Работать не просто с ключевыми словами, а с интентом – зачем человек задал этот вопрос.
- Контент в формате вопросов и ответов, списки, таблицы, блоки FAQ – чем проще вытащить факт, тем лучше.
- Помогать разметкой для FAQ, HowTo, статей, организации, авторов – это не обязательно, но дает дополнительный бонус.
Как AI решает, кому верить
И генеративный поиск, и чат-модели хотят одного – оперировать достоверными данными. Чем меньше шансов ошибиться или выдать дезинформацию, тем лучше. Но они не проверяют источники по единой схеме. Системы собирают «признаки надежности» по кусочкам.
Вот как расшифровывается система E-E-A-T, которую мы упоминали ранее:
Опыт (Experience) – есть ли в материале живые кейсы, реальные примеры, понятно ли, что автор сам разбирается в теме на практике.
Экспертиза (Expertise) – точные термины, глубина вместо поверхностного пересказа, ссылки на исследования или первоисточники.
Авторитет (Authority) – как часто бренд упоминают другие, кто на него ссылается, какая у домена репутация.
Доверие (Trust) – не противоречит ли информация сама себе, понятно ли, откуда взяты факты, нет ли ошибок в данных.

Если переводить на человеческий язык: и поисковики, и AI-ассистенты пытаются угадать, можно ли верить этому сайту. Разница только в том, на какие именно сигналы они обращают внимание в первую очередь.
— Есть еще один важный момент – брендовый авторитет (Brand Authority). Речь про то, как часто компанию упоминают в профессиональных материалах: в СМИ, исследованиях, обзорах, дискуссиях. Чем больше разных площадок ссылаются, тем выше шанс, что AI сочтет достоверным источником, — отмечает Елена Салтыкова.
Чем отличаются подходы:
Google – опора на индекс и внешние сигналы. Для Google E-E-A-T складывается из таких факторов: качество текстов, кто и как ссылается на сайт, как люди ведут себя на странице, ищут ли бренд по названию, какая у домена репутация в целом. Поэтому сайты, которые хорошо раскачаны в классическом SEO, чаще выигрывают и в генеративной выдаче.
Чат-модели – упор на то, как написан текст. LLM-системам важнее то, насколько текст удобен для чтения и парсинга. Им нужно, чтобы материал был логичным, полным, с понятной структурой, с явными ссылками на источники и контекстом – кто автор и о чем бренд. Проще говоря, модель должна с легкостью «считать» в материал и вытащить из него нужные факты, не продираясь через воду и хаотичную структуру.

— Если вы прокачиваете E-E-A-T, это почти всегда работает в плюс и для позиций в Google, и для цитируемости AI-ассистентами. Но не ждите, что алгоритмы совпадут полностью — это разные системы с разными приоритетами, — добавляет тимлид группы SEO инновационного digital-хаба Wunder Digital.
Из-за чего сайты выпадают из поля зрения AI
Даже ресурсы с качественным контентом часто остаются за пределами AI-ответов. Основные причины выглядят так.
1. Отсутствие прямых и коротких формулировок. Суть материала скрыта за длинными вступлениями и объемными абзацами. Модель не может оперативно извлечь конкретный факт.
2. Слабая структура. Недостаточно подзаголовков, списков, таблиц, блоков FAQ. Либо отсутствует разметка Schema.org, либо она настроена с ошибками.
3. Контент не содержит новой информации. Материал повторяет то, что уже опубликовано у конкурентов, без собственных кейсов, данных или исследований. У системы нет оснований выбирать именно этот источник.
4. Несоответствие пользовательскому запросу. Страница ориентирована на коммерцию, тогда как пользователь и AI ищут объяснение, инструкцию или чек-лист.
5. Недостаточные сигналы доверия. Мало внешних ссылок, авторы не указаны, отсутствуют отсылки к авторитетным источникам, бренд редко упоминается за пределами своего сайта.
Как нейросети распознают низкокачественный контент
Нейросети не маркируют текст как «созданный ИИ» только на основании его происхождения. Они анализируют качество через характерные паттерны.

К признакам слабого материала обычно относят:
- повторы, шаблонные обороты, одни и те же конструкции;
- низкую плотность смысла на единицу текста (вода);
- общие рассуждения без опоры на данные;
- однообразный ритм и тональность (без смены интонации и акцентов).
— Когда текст построен на общих фразах и не дает новой информации, он будет оценен как низкокачественный. И неважно, кто его создал – человек или нейросеть.
Сам по себе AI-контент не проблема. Проблема – это пустой, вторичный и бесполезный материал, — уверена Елена Салтыкова.
Рекомендации
Появление AI-поиска не отменяет основные принципы работы с контентом. И Google, и чат-модели предпочитают экспертные материалы, размещенные на авторитетных источниках. Но их способы оценки «качества» различаются.
Google больше завязан на традиционные SEO-метрики: какие сайты ссылаются на вас, как организован ваш ресурс, как пользователи с ним взаимодействуют, насколько силен домен в целом.
Чат-моделям нужен текст, который легко читать и анализировать: логичный, подробный, с четкими формулировками. И главное – из него должно быть просто вытащить конкретные факты.

Для видимости в AI-поиске потребуется работать в двух направлениях одновременно:
1. Укреплять позиции в классической выдаче и повышать узнаваемость бренда;
2. Выстраивать контент так, чтобы он был логичным, насыщенным и позволял системе без труда забирать из него нужные фрагменты.
В эпоху AI-поиска вырываются вперед уже не оптимизаторы, а эксперты – сайты, которые стали главным источником информации в своей сфере.