Яндекс выложил в сеть большой датасет для рекомендательных систем


Яндекс представил Yambda (Yandex Music Billion-Interactions Dataset) - крупнейший в мире открытый датасет для рекомендательных систем. Он содержит почти 5 миллиардов обезличенных взаимодействий пользователей с треками из стримингового сервиса «Яндекс Музыка», пишет digitalbusiness.kz
Датасет призван ускорить глобальные исследования и разработки в области рекомендательных алгоритмов. Он может использоваться для тестирования и обучения моделей не только в сфере потокового аудио, но и в электронной коммерции, социальных сетях и видео-сервисах.
Зачем нужен Yambda
Исследования в области рекомендательных систем сталкиваются с нехваткой современных и масштабных наборов данных. Многие открытые датасеты устарели или слишком малы. Например, набор Million Playlists от Spotify недостаточен для промышленного уровня, а Netflix Prize ограничен объемом и временными метками. Данные Criteo Click Logs - без документации и идентификаторов. Из-за этого существует разрыв между академическими разработками и реальными задачами индустрии. Yambda решает эту проблему: исследователи смогут создавать, тестировать и внедрять более точные модели рекомендаций.
Что внутри Yambda
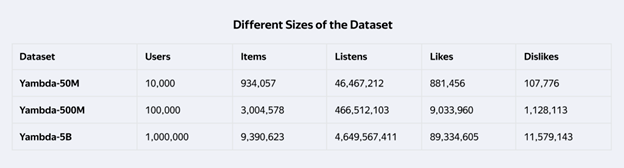
- 4,79 млрд пользовательских взаимодействий за 10 месяцев;
- данные от 1 млн пользователей и по 9,39 млн треков;
- два типа обратной связи: прослушивания и лайки/дизлайки;
- эмбеддинги треков и обезличенная информация о них;
- флаг is_organic для разграничения органических и рекомендованных действий;
- временные метки всех событий для анализа динамики поведения;
- Все данные обезличены, а сами файлы представлены в формате Apache Parquet™, совместимом с системами обработки больших данных (Spark, Hadoop, Pandas, Polars).
Разные версии и оценка моделей
Для оценки качества алгоритмов используется подход Global Temporal Split (GTS), который подразумевает разбивку данных по времени и позволяет сохранить естественную последовательность событий. При использовании подхода Leave-One-Out из истории каждого пользователя в тестовый набор данных откладывается только последнее подтверждённое взаимодействие, что может привести к нарушению временных последовательностей в обучающих и тестовых выборках. GTS исключает эту ситуацию и гарантирует более реалистичное тестирование модели, при котором имитируются реальные условия, а данные из будущего недоступны.
Бейзлайны для сравнения новых подходов к разработке рекомендательных систем были получены при тестировании алгоритмов MostPop, DecayPop, ItemKNN, iALS, BPR, SANSA и SASRec. Использовались стандартные метрики, в том числе:
- NDCG@k — качество ранжирования;
- Recall@k — способность генерировать релевантные рекомендации;
- Coverage@k — разнообразие каталога.
Доступ
Yambda доступен на Hugging Face, что упрощает доступ для исследователей по всему миру.
Может быть интересно:
Никаких наличных, «живая поддержка» и авторские заведения. Тестируем приложение Яндекс Еда