7 вызовов для тех, кто хочет создать большую языковую модель на казахском


ИT-компании QazCode и DAR Tech подписали меморандум о партнерстве, чтобы совместно развивать IT-услуги в стране. В конце октября на базе DAR University прошел NLP-митап, где дата-сайентист из QazСode (дочерняя IT-компания Beeline Казахстан) Бексултан Сагындык рассказал, как казахский язык интегрируется в эпоху LLM. Собрали краткие тезисы спикера на Digital Business.
Open-source модели недостаточно хороши
— На Hugging Face представлено 636 моделей для казахского языка, что относительно немного. Но 636 — это не конечная цифра, потому что в основном это модели с преобладанием крупных языковых групп: на английском, французском или китайском. В таких моделях может быть казахский, но они некорректно работают на нем.
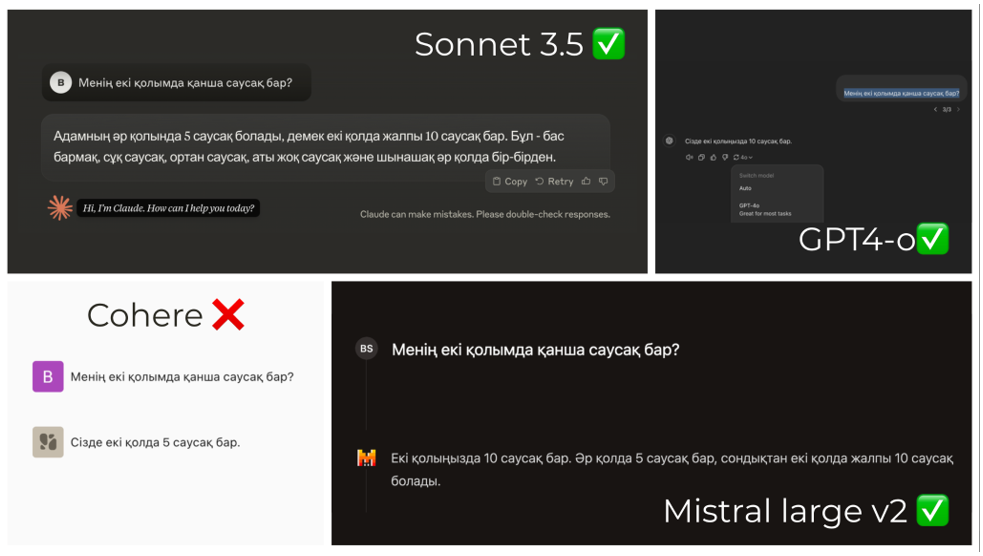
Я проверил относительно популярные open source-модели, такие как Llama, Mistral, Phi, Qwen, Gemma. Ниже на картинке ответы этих моделей на вопрос «Менің екі қолымда неше саусақ бар?».

Лучше всех справились Sonnet 3.5, GPT 4-0, Mistral large v2. Но эти модели доступны только через API, которые нельзя использовать бизнесу с данными, защищенными NDA. Например, если мы хотим внедрять языковые модели в сервисы государства, то использовать можно только open-source модели, которые можно установить на сервер. А если все же данные не защищены NDA, то использование API также имеет минусы в виде больших костов.
Мало данных на казахском языке
— Даже если собрать все доступные тексты на казахском языке из интернета, библиотек и архивов различных организаций, этого все равно будет недостаточно для полноценного обучения большой языковой модели с нуля. Большие языковые модели требуют обширных и разносторонних данных, которые охватывают широкий спектр лингвистических, культурных и семантических особенностей языка в различных контекстах — от литературы до науки.
Отсутствие таких богатых данных ставит перед разработчиками серьезные ограничения. Часто приходится прибегать к переводу текстов с других языков, особенно с английского. Но это не решает проблему, поскольку обучение языковой модели с нуля (pre-training) требует исключительно качественного и аутентичного материала. В итоге приходится адаптировать уже существующие модели, дообучая их казахскому с помощью дополнительных этапов обучения (continual pre-training) или применять альтернативные методы, такие как Instruct Tuning, RLHF и другие. Эти подходы позволяют компенсировать нехватку данных.
Сложности при дообучении языковых моделей
— В экспериментах мы хотели сохранить старые языки модели и дообучить новому — казахскому. По ходу экспериментов столкнулись с трудностями. Пример: при дообучении Gemma казахскому модель «тупела» на смежном языке, в этом случае — на русском. Так происходит из-за того, что в русском и казахском много смежных токенов (частей слов).
Необходимость больших ресурсов для создания модели
— Чтобы обучать большие языковые модели, требуется много вычислительных ресурсов, которые вы можете получить путем аренды или покупки серверов с GPU для решения высоконагруженных задач, но это очень дорого.
Этот важный челлендж требует развития инфраструктуры. Она необходима для поддержки проектов по созданию моделей на казахском языке или других инициатив с высоким требованием к компьютерным ресурсам, многие из которых имеют не только научный, но и научно-прикладной характер.
Мало дополнительных решений для казахского языка
— Допустим, вы собрали данные для LLM. Дополнительный челлендж на вашем пути — необходимость предварительной очистки и обработки данных. Для этого требуются маленькие решения, например, NER, spell-checking, Language detection, которые нужно разработать для казахского языка. В итоге вместо того, чтобы обучать большую языковую модель c высоким уровнем качества, дата-сайентисты вынуждены также заниматься разработкой вспомогательных решений, что требует много времени.
Необходимость real-time решений для пользователей
— Если все сложилось удачно и вы успешно обучили LLM, вам нужно будет ее внедрить, чтобы пользователи в режиме реального времени могли пользоваться моделью и делать ее «умнее». Что-то наподобие ChatGPT. А это отдельное инженерное решение (включая кэширование, стриминг, ускорение инференса, компрессия и т.д.), которое должно быстро обрабатывать данные и выдавать ответы.
Мало опыта в создании больших языковых моделей
— В Казахстане очень мало специалистов в сфере NLP, и еще меньше специалистов, которые обучали LLM. Все команды, которые на данный момент занимаются этим, делают это впервые. А значит, что всем им нужно тестировать много гипотез и пройти длинный путь, чтобы в итоге получился хороший продукт.
