Казахская языковая модель на основе ИИ опубликована в открытом доступе

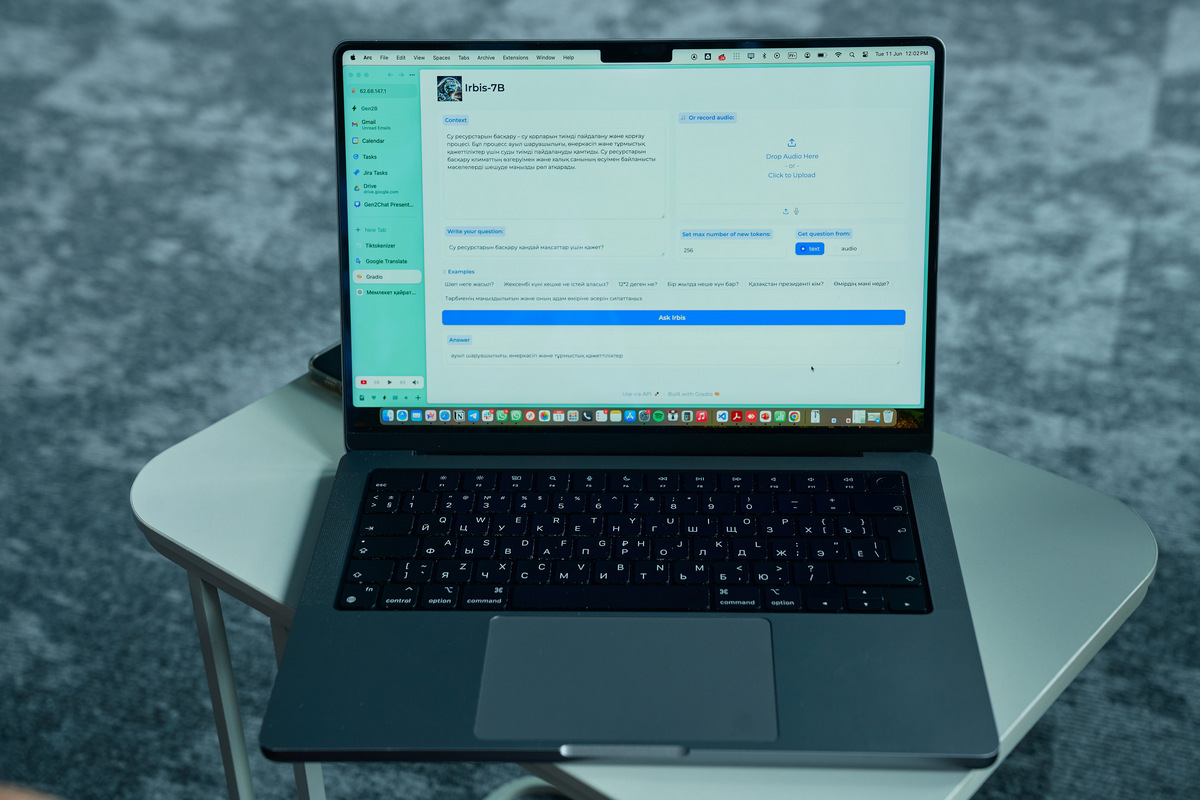
Это первая национальная языковая модель с открытым исходным кодом. IrbisGPT обучена на большом наборе данных на казахском языке. Теперь любой человек сможет протестировать нейросеть и сделать свой вклад в ее обучение на казахском.
IrbisGPT – общественная некоммерческая инициатива, разработанная в сотрудничестве с MOST Holding и студией Gen2b.ai, специализирующейся на применении искусственного интеллекта в бизнесе.
– IrbisGPT – это пионерский проект в области развития казахского языка через применение искусственного интеллекта. Цель инициативы – сохранение и распространение государственного языка и его интеграция в современные цифровые технологии для развития общества, экономики и науки в Казахстане. Мы выложили проект в открытый доступ для того, чтобы собрать вокруг него комьюнити и дать возможность каждому протестировать и сделать свой вклад в обучение модели, – рассказал фаундер проекта Бахт Ниязов.
Актуальная версия IrbisGPT демонстрирует отличный потенциал для обучения. По словам разработчиков, подобные оупенсорсные модели либо пытаются ответить на английском, либо просто «сыпят» случайными словами на казахском. Национальная языковая модель, напротив, на вопросы без контекста отвечает достаточно развернуто и правильно. Так, IrbisGPT дает ответы на государственном языке на вопросы «шөп неге жасыл» (почему трава зеленая?), знает, кто президент Казахстана, сколько дней в году, и даже может рассуждать о смысле жизни.

– За короткий срок Irbis LLM разобралась с построением слов и грамматикой казахского языка. Сейчас она умеет обрабатывать входящую информацию, отвечать на простые вопросы и способна работать с контекстом. Это позволяет подключить ее к актуальным базам знаний, например, к налоговому кодексу. Также, благодаря более эффективному токенизатору, скорость генерации текста увеличилась от 3 до 5 раз по сравнению с моделями GPT. Для обучения модели мы собрали 20 Гб «сырых» данных из новостей и статей на казахском языке, расширив ее словарь почти в три раза. Однако этого недостаточно, мы надеемся на предоставление качественных данных со стороны госорганов для усовершенствования IrbisGPT. У нас есть четкий план, и самое главное – навыки по созданию модели следующего поколения, используя все самые последние достижения в области больших языковых моделей, – рассказал CEO Gen2b.ai Армен Атаян.
Итоговый словарь токенизатора содержит более 60 тысяч токенов. В планах команды создать модель в более совершенной архитектуре для использования в различных отраслях.
Скачать предобученную версию можно по ссылке.