Как принять огромный проект из аутсорса в инхаус и выжить? Опыт Altel

Более 10 лет в Tele2 Казахстан и Altel не было инхаус-разработки в направлении Digital. Но в начале 2022 года компания, которая управляет двумя брендами, по разным причинам решила собрать свою команду. С какими трудностями столкнулся бизнес в переходный период — и как выбрался из ситуации? Об этом рассказали Lead of Backend Development Айдар Джапенов и Lead of Frontend Development Максим Нам.
Почему Tele2 и Altel отказались от аутсорса?
Айдар: — У Tele2 и Altel есть 2 основных мобильных приложения для B2C — Tele2 и Altel на iOS и Android, а также множество веб-приложений. Под капотом — большое количество сервисов, которые стали тылом нашего Frontend-слоя.
Аутсорс vs. Инхаус
Для начала кратко расскажу о плюсах аутсорс-разработки.
Найм и поддержка собственной команды разработки — зачастую трудозатратный процесс, который требует больших расходов на зарплатный фонд, обучение сотрудников, содержание офиса и оборудования, а также закупку ПО. Аутсорс может быть полезен для экономии затрат, когда бизнес только начинает свой путь. Но работает это в краткосрочной перспективе.
Для решения важных задач могут понадобиться большие мощности. И аутсорс-компании закрывают вопрос масштабируемости гораздо быстрее и гибче, потому что у них есть возможность релокации специалистов из проекта в проект.
Еще обычно у аутсорса есть готовые наработки и решения, которые в моменте помогут быстро решить задачи компании.
Когда-то именно по этим причинам Tele2 и Altel передали задачи по разработке мобильных приложений на аутсорс. Нужен был фокус на бизнесе. Спрашиваете, что изменилось? Пришло время затронуть аргументы «За» инхаус-команду.
Инхаус в долгосрочной перспективе дешевле, чем аутсорс. Кроме этого, работа компании становится более эффективной, когда компетенции развиваются внутри команды. Когда появляется множество сервисов, их надо поддерживать постоянно. И обычно инхаус-команда способна реагировать быстрее, чем аутсорс.
Еще один момент — увеличение контроля над разработкой. Это основной фактор для бизнеса, который хочет управлять эффективностью внедряемых решений и понимать, что происходит внутри.
А еще нужно контролировать безопасность. Со временем кодовая база растет, у компании становится больше клиентов. Закрывать вопросы конфиденциальности данных своими силами проще и безопаснее.

После анализа плюсов мы и решили создать инхаус-команду.
Было больно? О, да!
Максим: — Теперь поговорим о том, почему процесс перехода из аутсорса в инхаус — это больно.
Во-первых, скорость. Бизнес не стоит на месте — и ему нужно релизить новые фичи. У новоиспеченной команды не было времени на адаптацию, поэтому она не всегда успевала тушить пожары и выпускать что-то новое.
Во-вторых, не выстроенная система онбординга. В команду приходит много новичков, и иногда процесс адаптации специалистов был болезненным.
В-третьих, ответственность. Работая с вендором, всегда можно перенести ответственность за факапы на него. В инхаусе так не работает. Но люди не любят принимать большую ответственность сразу.
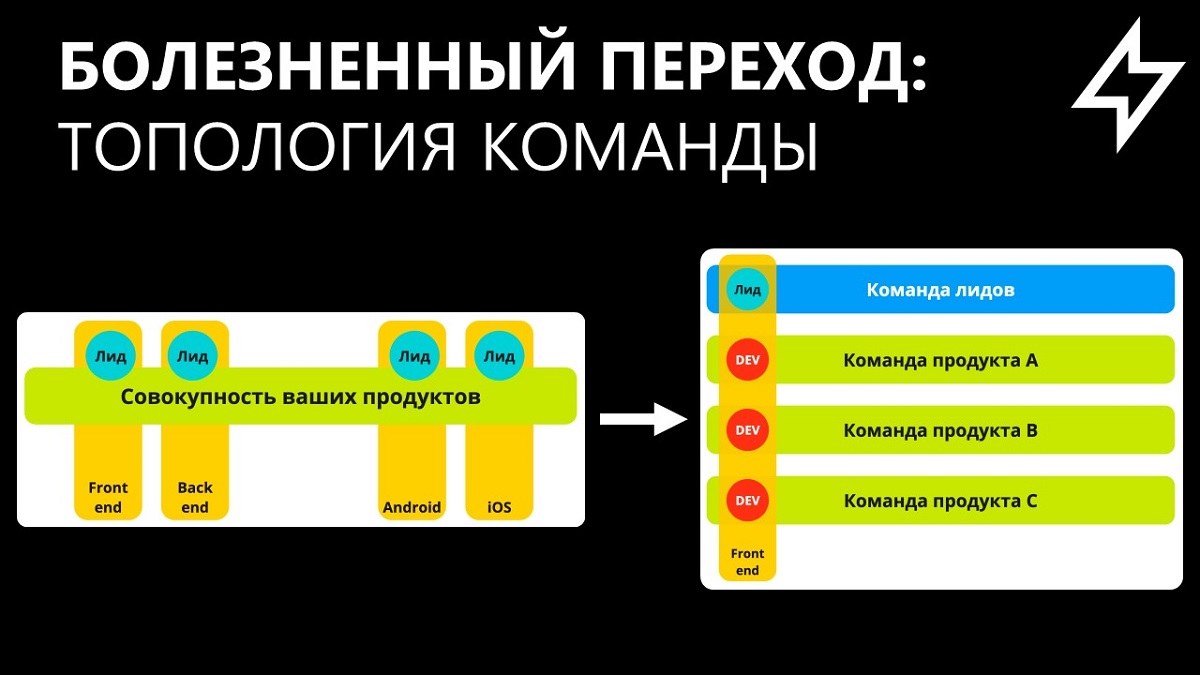
Важный момент – топология команды. Структура подразделений на аутсорсе подразумевает поток заказов от одного заказчика. Специалисты технологического слоя подконтрольны лидам. Соответственно, и структура проектов, и процессы релиза подстраиваются под топологию. В инхаусе совсем не так: существует несколько продуктовых стримов, у каждого стрима своя команда разработки. Лиды находятся обособленно — они не контролируют поток задач напрямую. И та структура, которая была в аутсорсе, не будет работать по привычной схеме.
Отдельный блок вопросов — по поводу легаси-кода (устаревшего либо кода без технической и тестовой документации — прим. Digital Business), потому что его понятие может быть очень размытым. Я часто общаюсь с коллегами по сфере, с друзьями и спрашиваю: «А что такое легаси-код?». Кто-то говорит, что это просто старый код. Но с такой логикой сегодняшние строки уже завтра тоже попадут под это понятие.
Либо это код, который трудно или дорого поддерживать. Именно из легаси вытекают еще 4 важных пункта нашего списка «болей» при переходе из аутсорса в инхаус:
- Неактуальные соглашения, которые были приняты аутсорс-командой
- Отсутствие инфраструктуры тестов как таковой
- Этап релиза
Команды в аутсорсе привыкли релизиться последовательно. Асинхронности как таковой не было. И в потоке задач и релизов для продуктовой команды такая логика не работает: стримы просто начали мешать друг другу.
- Вопрос выбора: переписывать или рефакторить код?
Рефакторинг — это тоже не всегда выход, даже если мы уберем момент рерайта кода. Процесс обновления может длиться бесконечно, потому что идеальный код находится только у нас в голове. И если команда не видит конечной цели, то итерационный рефакторинг станет невозможным.
Также мало кто делает нужную документацию. И еще меньший процент команд создает все правильно. Это приводит к тому, что ты либо получаешь талмуд с документацией, которую сложно обновлять и читать, либо вообще полное ее отсутствие.
Все это – болезненные вопросы. Но боль — не всегда плохо, особенно если ты можешь говорить о ней публично. Такой подход дает фокус на людях и помогает разъяснять сотрудникам ценность твоей работы для конечного клиента.
Проблемы на Backend-е
Айдар: — Помимо производительности, у нас был ряд других проблем. Например, архитектурный коллапс между REST и GraphQL, отсутствие Observability и журналов инцидентов.
Частые падения
В день могло происходить по 4 инцидента. Самый долгий простой — 11 часов. Наши DevOps-ы делали все, что могли на уровне инфраструктуры, добавляли мощности, но этого было недостаточно. Backend жил двойными стандартами, так как iOS и Android обращались в сервисы посредством технологии REST, а веб — через GraphQL.
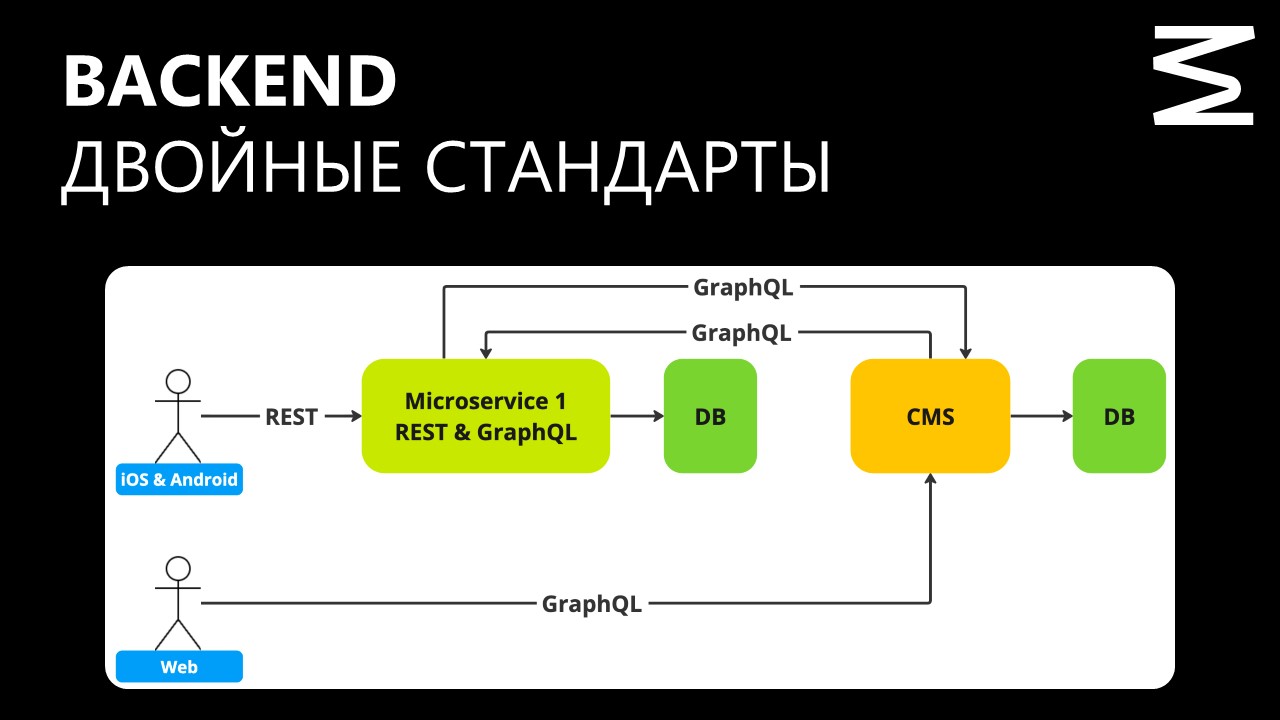
Отсутствие Observability
У нас не было ни метрик, ни читаемых логов, ни трейсингов. Так как у нас межсерверные взаимодействия, мы не понимали от начала до конца, как выглядит весь путь запроса. В дальнейшем, даже когда настроили Observability, информации все равно не хватало, потому что мы использовали агента, и в рамках коммуникации с другими системами ряд запросов получал статус «200» (Код ответа, который интерпретируется как «хорошо» — прим. Digital Business).
Казалось бы, «200» — это успешно, но нам нужны были детали. Не хватало тел запроса и ответа. И получалось так, что в той системе, в которой мы получали «200», вся логика была зашита внутри тела. То есть нужно было забираться и выяснять, какие статус-коды там есть.
Проблемы с соединениями…
… или connection timeout. Когда пользователь заходил в приложение, экраны прогружались через раз.
Отсутствие базы инцидентов
Очень важный момент, потому что до этого мы не понимали, с какими проблемами сталкиваемся, насколько часто и как их решаем.
Из-за этих моментов страдали все. В том числе наши клиенты. А бизнес терял деньги, потому что время от времени падали сервера, и мы не могли внедрять новые фичи. Требовался разумный рефакторинг сервисов, изменения в архитектуре, появилась необходимость во внедрении инструмента для отслеживания инцидентов. Что мы и сделали.

Как решались проблемы на Backend-е
Для устранения проблемы с отсутствием базы инцидентов ввели практику Post Mortems. О ней вкратце рассказано в книге Site Reliability Engineering.
Цель Post Mortems — понять, какая проблема произошла и почему, а также не допускать ее в будущем. Подход позволяет структурировано работать с неполадками и делать так, чтобы в будущем не допускать тех же ошибок.
Ситуацию с отсутствием Observability помогли решить DevOps-инженеры, которые внедрили единое окно. Как инструмент визуализации используем Grafana, подключили OpenTelemetry для вывода трейсов, Prometheus в качестве коллекции всех метрик и Grafana Loki для сбора логов на сервисах.
Проблемы соединений решили через небольшой рефакторинг. Обновили те трейсы, которые требовали детализации по запросам-ответам. И начали видеть всю картину более прозрачно.
Так же поступили с проблемой connection timeout. Оказалось, что на стороне клиента каждый запрос создавал отдельное соединение. В данном случае помог connection pool, который позволил управлять процессами и убрать таймауты.
Вопрос с падениями решили с помощью Sentry. Это позволило сгруппировать часто повторяющиеся ошибки. У Sentry есть хорошая возможность назначать ответственного, чтобы распределять нагрузку по людям равномерно. Важно: Sentry — это большое open source решение, состоящее из множества компонентов. Во многих случаях, если нет большой экспертизы, лучше смотреть в сторону облака, где все уже настроено и готово к работе.
Для решения проблемы с производительностью ввели анализ потоков. Наша ситуация была связана с зависанием больших потоков, поэтому мы начали делать thread dump, для этого использовали платформу fastthread.io.
Проблемы перехода на Frontend-е

Максим: — Есть вот такой мем: фронтендер чиллит, стрижет газон и думает, что ураган его не коснется. Но катаклизм уже близко. История, когда на фронтенде все красиво, а бекенд падает, в продукте не работает.
Но кроме падающего backend-а у frontend-а был ряд своих проблем.
Технические долги
Что я видел, когда открывал IDE: миллиард «тудушек» в каждом из компонентов. Везде, где только это возможно, были мины в виде хаков, заложенные до перехода. И это все нужно было исправлять или изолировать.
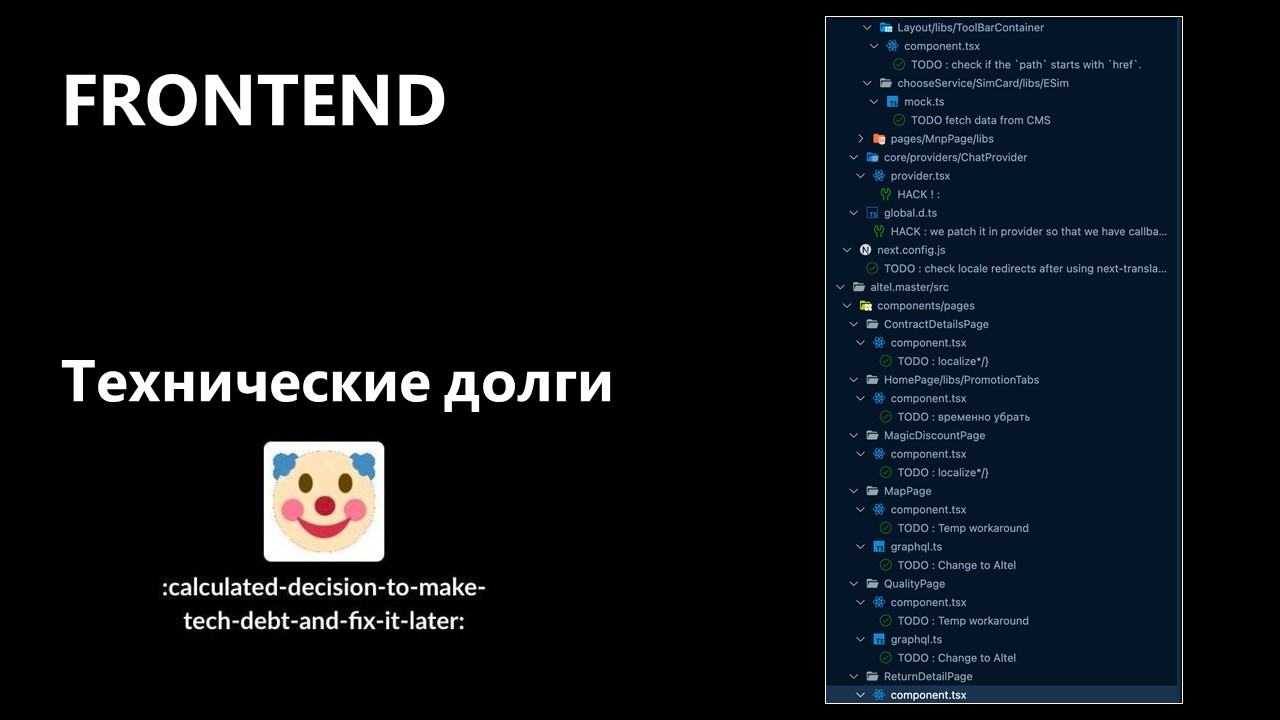
Недостаточная документация
Если Айдар тушил пожар, то я пришел, когда все прогорело. Были те стримы и команды, которые стартовали свои проекты разрозненно. Получилось, что каждая команда сама определяет свой стек. Где-то JavaScript, где-то TypeScript, кто-то уже «едет» на REST, кто-то на GraphQL. Это сильно мешало в первое время.
Отсутствие тестов
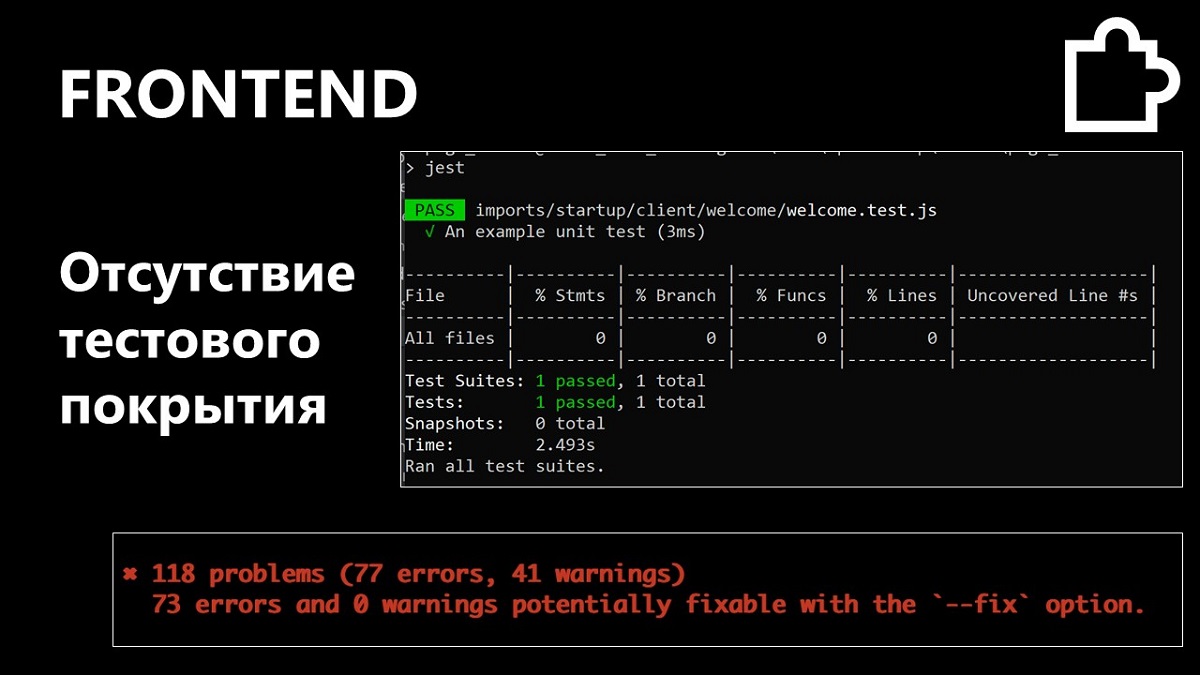
Отсутствие соглашений и общей стандартизации
Конфигурация линтеров и сборщиков, клиентская доступность = перфоманс самого приложения, ведение первичной документации, интеграционные контракты с backend, политика релизов.
А еще:
- Несовместимость с новыми подходами
- Низкая производительность
- Сложность поддержки и обновления
- Болезненные релизы
Как решались проблемы на Frontend-е
Во-первых, мы навели порядок в тех группах репозиториев, где это возможно. Это, конечно, не проведение глобального рефакторинга или переписывание приложения, но тоже полезная вещь.
Во-вторых, сфокусировали внимание на команде. Например, ввели эффективный и достаточно короткий онбординг.
В-третьих, изолировали core-проект. Был очень большой монорепозиторий. Он и сейчас есть, но по крайней мере не вызывает таких проблем, которые были изначально.
Также мы изолировали кастомные пакеты в Nexus. Что-то получилось изолировать, что-то нет. Это касается и самописных решений, и тех решений, которые все еще в текущем монорепозитории.
А еще:
- Провели постепенный и точечный рефакторинг
А именно: рефакторинг тех вещей, которые были указаны в техдолгах. Это уже стартовавшие проекты в инхаусе, которые нужно переделать под общий стандарт. И написали минимум документации, которую легко постоянно обновлять.
- Создали инфраструктуру тестов
Сложность здесь — в определении соглашений в команде о спецификации тестов и проценте покрытия.
- Настроили перезапуск Node каждого отдельного воркспейса в моно-репозитории по расписанию
Без даунтайма при переполнении памяти. Со временем он стал не нужен, но как временное решение подходит очень классно.

Наши выводы
Выводы после переезда
Айдар: — Нужно использовать все, что есть под рукой. И не бояться брать даже платные инструменты, ведь это поможет избежать повторяющихся ошибок на первом этапе, да и в будущем тоже. Также нужно заводить базу инцидентов. Для анализа неполадок нужно где-то хранить сведения о них.
Нужно пробовать все, потому что хуже вы уже не сделаете. При переходе из аутсорса в инхаус, да и в других стрессовых ситуациях, понадобится смелость. Стоит постоянно напоминать всем, что любое изменение и новое решение делается для клиентов.
Глобальное внедрение общих соглашений и конвенций — это отличное решение. Если соглашение не работает, его нужно обновить. Рефакторинг должен быть постепенным и итерационным, а не бесконечным и бесцельным.
Новые проекты нужно создавать по текущему согласованному стандарту, который знают все заинтересованные лица. Эта практика работает на всех этапах и слоях разработки.
Политика релизов решает боль с этапом обновления приложения. Каждый участник проекта должен знать, за кем релиз, в какой день его нужно провести и когда это невозможно.
Что нам уже сейчас дал переезд
Какие же плюсы от переезда мы уже смогли ощутить на себе? В целом отмечается множество положительных моментов, но вот три, пожалуй, самых важных:
Уменьшили количество и длительность простоев
Никто не идеален, и мы продолжаем стремиться к еще более бесперебойной работе наших сервисов. Но уже сейчас объем наших простоев существенно снизился.
Настроили процессы
Инхаус позволяет структуризировать разработку. Уже сейчас выработаны четкие процессы создания и поддержки существующего ПО, начиная от Agile и заканчивая методологией Post Mortems. Все это помогает быстрее разрабатывать более качественные продукты и сервисы для клиентов.
У нас быстрыми темпами начала развиваться экосистема с множеством собственных и партнерских сервисов. Например, пользователи наших приложений уже сейчас могут оплачивать онлайн-сервисы с виртуального счета, заказывать продукты или обменивать бонусы Күнделік. И дальше – больше.
Сервисы стали намного более безопасными
Безопасность пользователей – один из наших главных приоритетов. Переезд в инхаус помогает кардинально сокращать количество уязвимостей, в том числе способных повлиять на клиентов. Не будем спойлерить, но совсем скоро мы поделимся материалом как раз на эту тему – о серьезном повышении безопасности клиентов в наших приложениях.